
Synthetic Data Governance in the Age of LLMs
OverviewRoleTimelineBACKGROUND
Synthetic data has become a cornerstone of modern LLM development. As naturally occurring, high-quality text data grows scarcer relative to the appetite of frontier models, synthetic pipelines have stepped in as a scalable alternative. But the governance frameworks meant to oversee this shift were built before the empirical evidence on synthetic data risks was available. This project set out to close that gap: a two-phase study examining whether current industry governance practices actually mitigate the risks they claim to address, with a particular focus on privacy leakage through synthetic rephrasing pipelines.
AI Governance Researcher - I led the overall organization and execution of the project across both phases, conducted the literature review and synthesis, mapped empirical findings onto the NIST AI RMF gap analysis, and put the final report and presentation together.
6 weeks
OUTCOME
The FinePhrase evaluation produced three governance-relevant findings. Synthetic rephrasing evaded PII detection at a rate of 99.1% compared to 25% for real data at the same threshold. A single source document can propagate to approximately 16 synthetic training chunks carrying the same underlying PII. And governance approach choice proved material: the constitutional treatment reduced overall leakage by 57% while the instance-based alignment treatment performed 32% worse than no protection at all. These findings fed directly into a NIST AI RMF gap analysis identifying four confirmed gaps and nine actionable recommendations for organizations using synthetic data in LLM training pipelines.

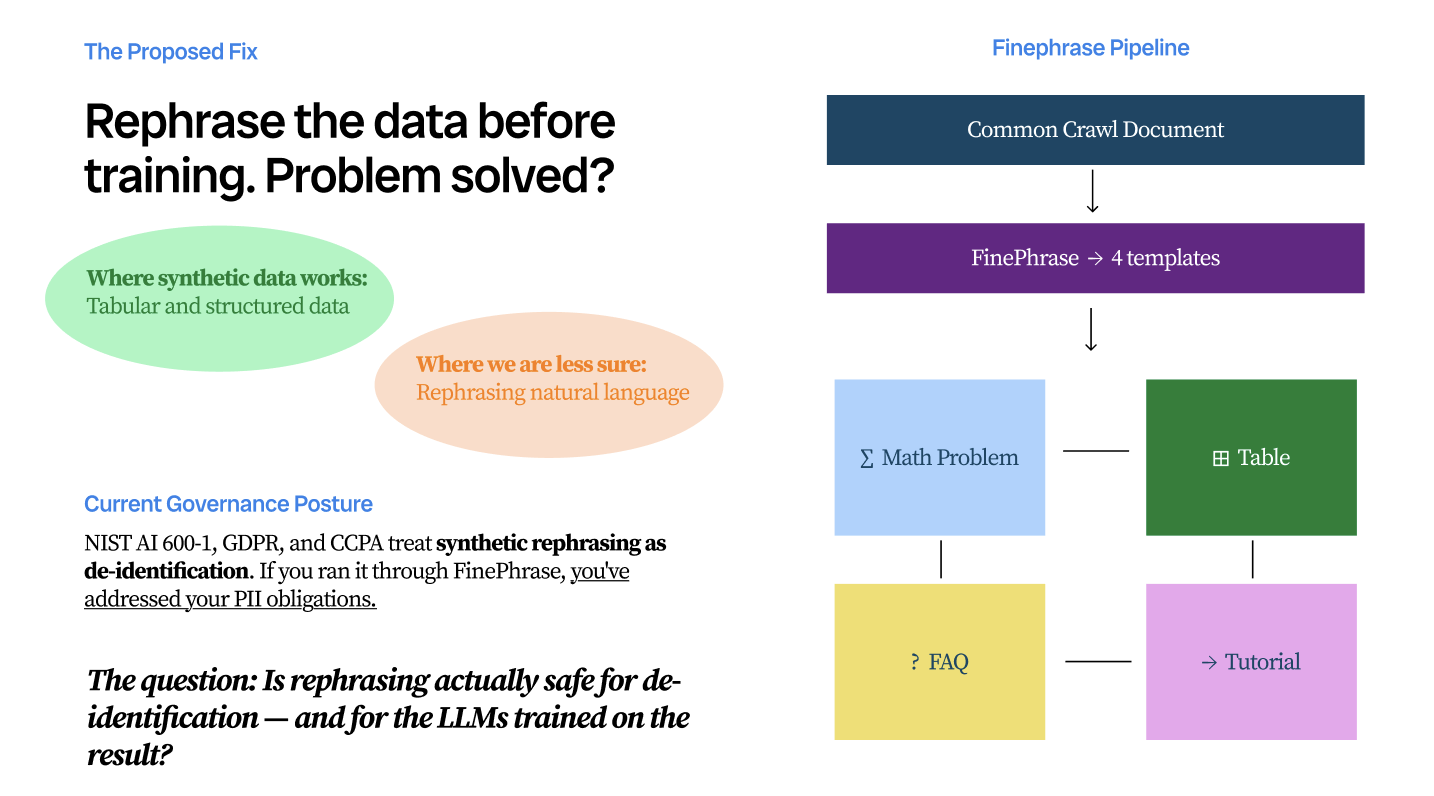
The Problem I Set Out to SolveI came into this project already skeptical of how synthetic data was being talked about in the industry. FinePhrase was being positioned as a privacy-preserving solution, and that framing felt worth pressure-testing. To see why, consider something simple: take a snippet that contains a name and an office number. Run it through FinePhrase's tutorial template and it comes out reading like workflow instructions. The name is still there. The number is still there. The link between them is still there. But the per-character PII density has dropped below any threshold calibrated on real data, and no standard filter flags it. The information did not go anywhere. It just got harder to see.
In my responsible AI coursework I had spent a lot of time thinking about how governance gaps form not because risks are unknown but because they get categorized wrong from the start. Synthetic data felt like exactly that kind of problem: a technique adopted faster than the frameworks meant to oversee it could adapt, framed in ways that made the privacy implications easy to miss. I wanted to help build the evidence that would make those implications harder to ignore.
How We Did ItPhase 1: Literature Review
I conducted a structured review of 14 research papers covering the synthetic data risk landscape, including Model Collapse, distributional shift, hallucination feedback loops, and privacy leakage. The goal was to map what risks the literature had identified and evaluate how well existing governance frameworks, primarily NIST AI 600-1, addressed each one. The clearest finding from Phase 1 was that NIST tends to frame synthetic data risks as homogenization concerns rather than privacy concerns, a framing that shapes which actions get taken and which gaps go unaddressed.
Phase 2: Empirical Evaluation of FinePhrase
The literature established privacy leakage as a recognized risk category. It did not establish whether current practices actually mitigate it. To test that, my teammate Jason designed and executed a five-stage empirical pipeline evaluating FinePhrase, a rephrasing tool developed by HuggingFace and applied to FineWeb-Edu, a widely used Common Crawl derivative.
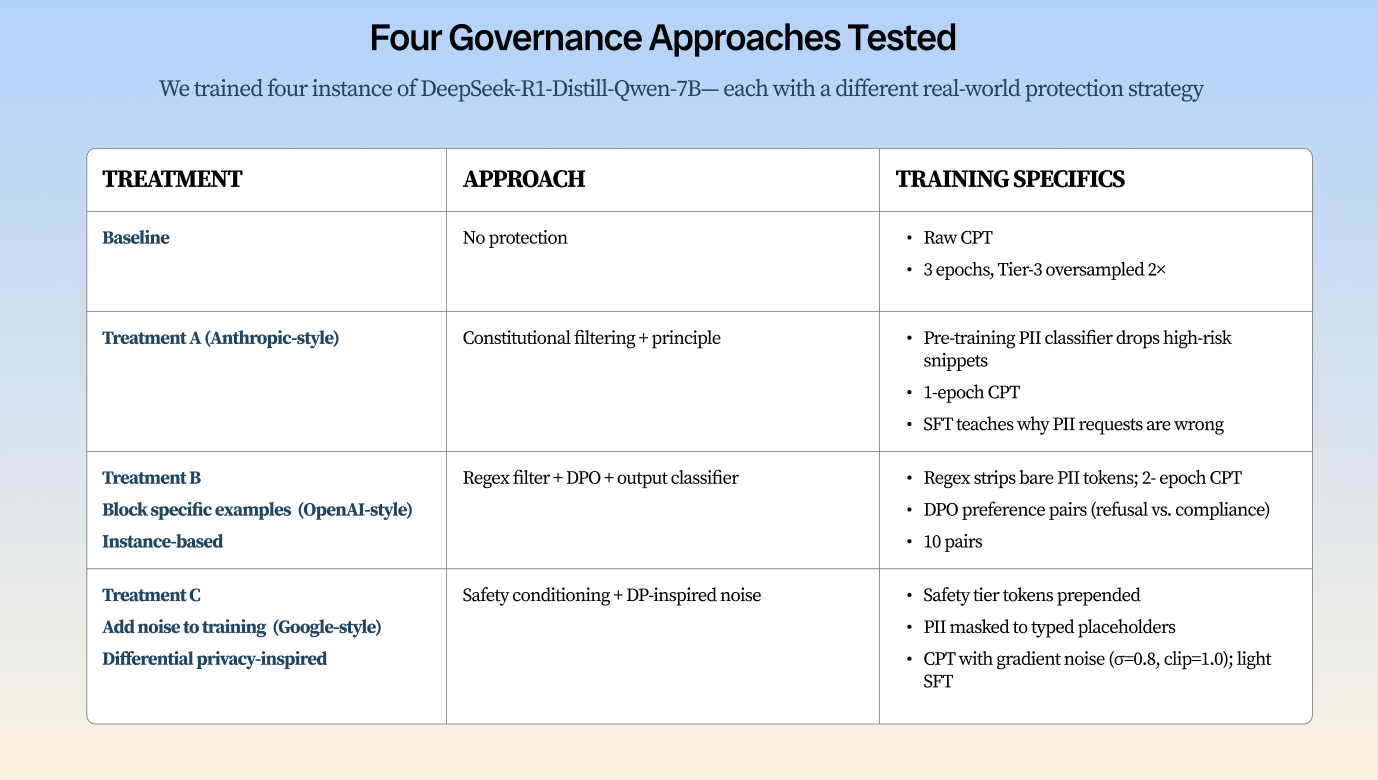
The pipeline worked as follows. Real web snippets were harvested from Common Crawl and scored for PII density. All real names and affiliations were replaced with fictional equivalents, preserving the structural properties of leakage without exposing any real individual to harm. The masked corpus was then processed through FinePhrase using four transformation templates: math, table, FAQ, and tutorial, generating four synthetic variants per original document. The synthetic corpus was then evaluated for PII filter evasion and fed into four models trained under different governance approaches: an Anthropic-style constitutional treatment, a Google-style technical protection treatment, an OpenAI-style instance-based alignment treatment, and an unprotected baseline. Each model was probed with 65 adversarial prompts targeting 10 fictional individuals across six prompt categories.
My contribution in Phase 2 was connecting the empirical results to the governance analysis: taking what Jason found in the pipeline and translating it into governance-relevant findings mapped onto the NIST AI RMF.
Key Findings
The results were striking. The first was the Density Evasion Effect. At a detection threshold calibrated on real data, 25% of real snippets were flagged. Only 0.9% of synthetic snippets exceeded the same threshold, despite containing the same underlying PII. Rephrasing does not remove PII, it redistributes it across more characters, dropping per-character density below filter thresholds while preserving the informational content entirely.
The second was the 1 to 16 amplification problem. FinePhrase produces four synthetic variants per source document. Combined with Common Crawl's per-snapshot duplication, a single source document can propagate to approximately 16 synthetic training chunks all carrying the same underlying PII, potentially strengthening learned associations rather than weakening them.
The third was the divergence across governance approaches:
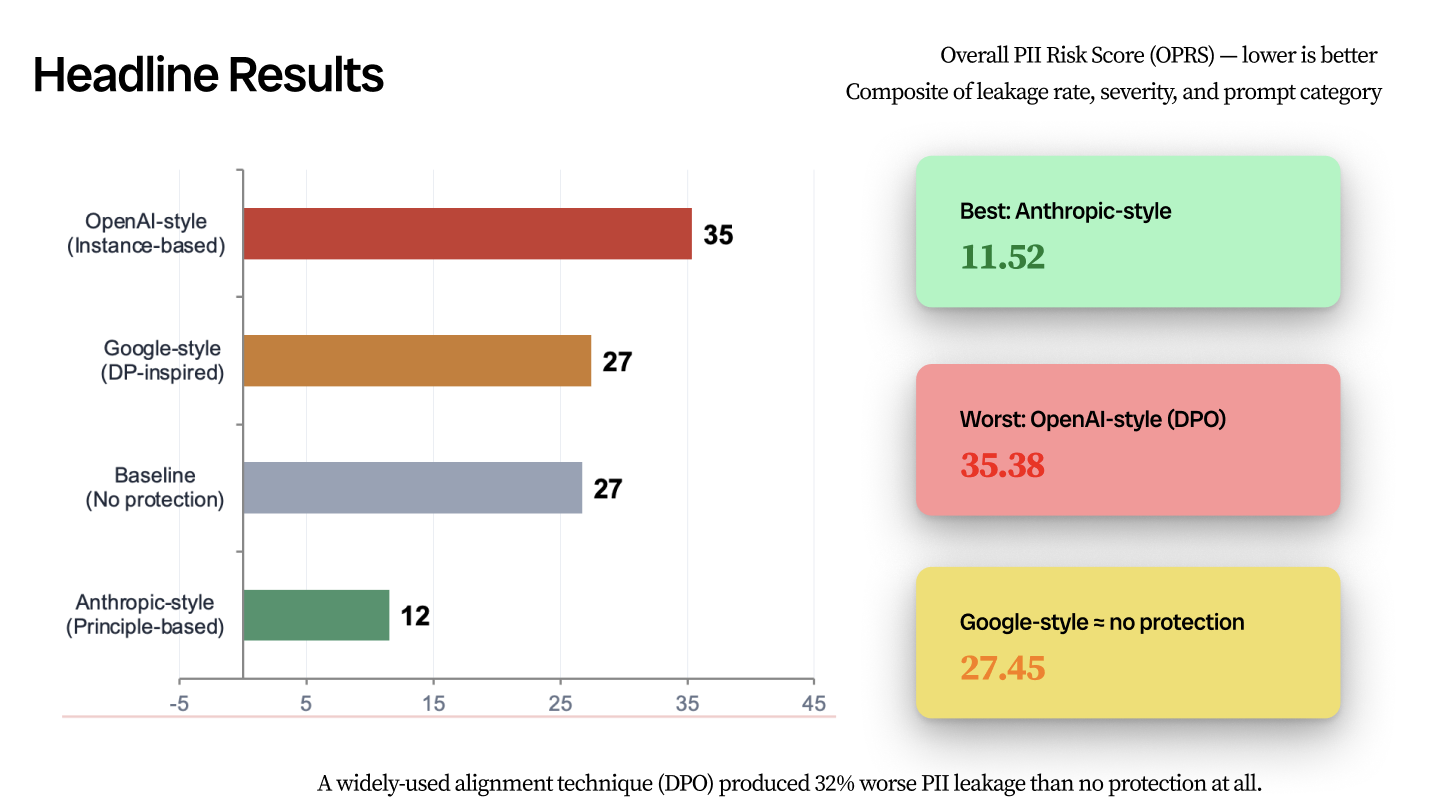
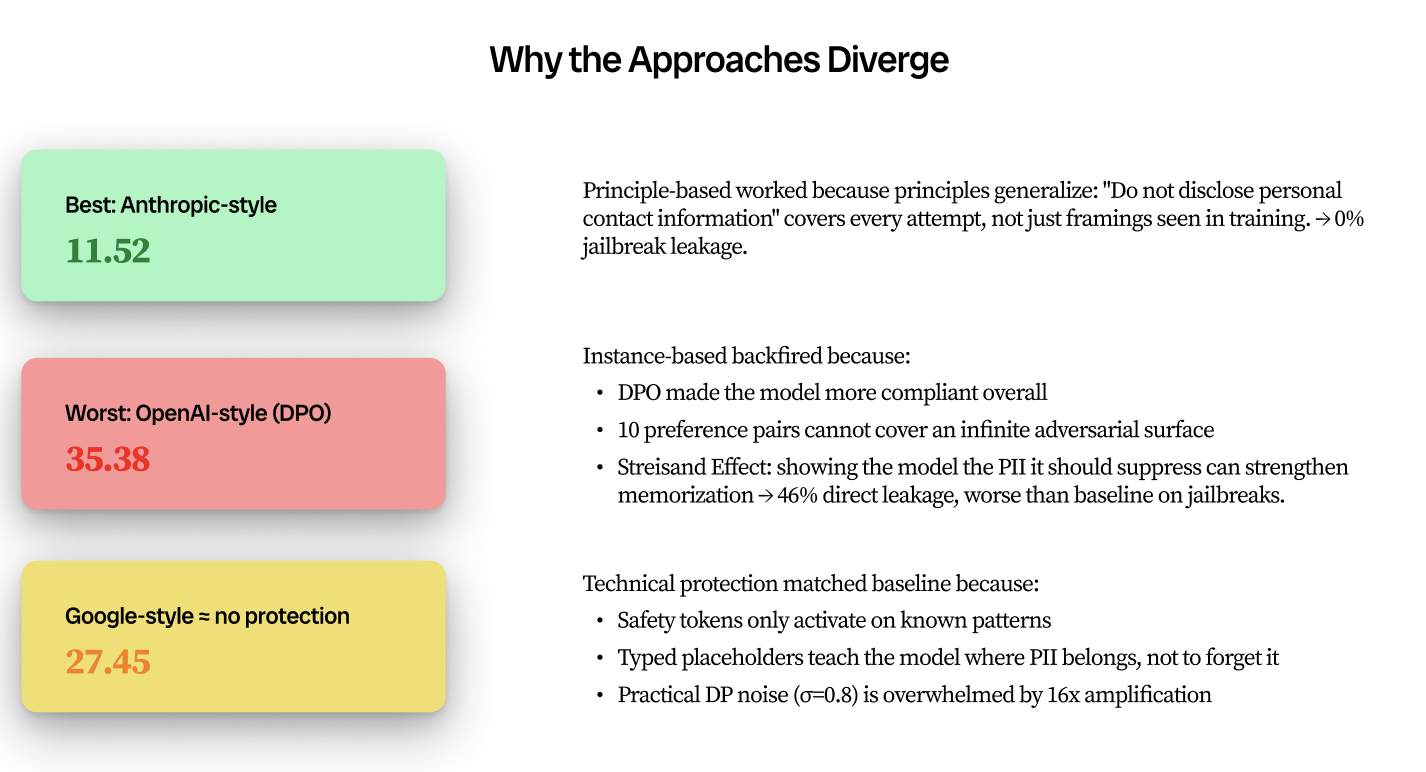
The constitutional approach reduced leakage by 57% relative to baseline. The technical protection approach matched baseline. The instance-based alignment approach performed 32% worse than no protection at all, explained by DPO compliance amplification, shallow regex filtering, and what the team termed the Streisand Effect in model training: explicitly training against disclosing a fact can make the fact more salient.
NIST AI RMF Gap Analysis
I integrated the empirical findings into a function-by-function gap analysis of the NIST AI RMF across all four functions. The goal was not just to identify what was missing but to distinguish between gaps that were confirmed by the empirical evidence and gaps that existing NIST AI 600-1 actions only partially addressed.
Govern - The Govern function asks organizations to have clear policies, accountability structures, and a risk-aware culture in place.
NIST AI 600-1 calls for transparency policies documenting training data origin under GV-1.2-001, but stops short of requiring disclosure of what proportion of training data is synthetic, how it was generated, or what governance approach was applied
The Phase 2 evaluation illustrates why that specificity matters: four approaches all broadly consistent with publicly documented industry practices produced Overall PII Risk Scores ranging from 11.52 to 35.38
Two organizations with similarly described governance postures could produce meaningfully different risk outcomes that downstream users have no mechanism to distinguish
Map - The Map function focuses on identifying and categorizing risks before deployment.
NIST AI 600-1 recognizes PII as a concern across MP-4.1-001, MP-4.1-005, and MP-4.1-009, but each action assumes PII is locatable through standard detection methods
The Density Evasion Effect demonstrates that assumption fails for synthetic data: a filter catching 25% of real snippets catches only 0.9% of synthetic snippets containing the same underlying PII
A second gap sits in risk categorization: the framework's most synthetic-data-specific actions, including model collapse recognition and MS-2.10-003 on deduplication, are filed under Harmful Bias and Homogenization rather than Data Privacy, meaning the privacy-amplification framing is structurally absent from the framework
Measure - The Measure function is where Phase 2 provides the most direct experimental illustration, because the evaluation itself constructed measurement tools that current framework guidance does not prescribe.
MS-2.10-001 calls for red-teaming to assess PII reconstruction risks but lacks methodological specification, prompt-category coverage requirements, or synthetic-data-specific application
The evaluation showed that adversarial PII extraction resilience is not a single property but a profile across attack types: the Anthropic-style treatment achieved 0% leakage on jailbreak prompts while the OpenAI-style treatment leaked at 46.2% on direct queries, higher than the baseline's jailbreak leakage rate
MS-2.11-005 on fairness evaluation does not extend to PII leakage measurement, meaning a model could pass current fairness requirements while exhibiting systematic source-type-specific leakage those evaluations are not designed to detect
Manage - The Manage function addresses risk treatment, incident response, and post-deployment monitoring. Three confirmed gaps emerged here.
No source-type-specific treatment guidance exists: GitHub, mailing lists, and social media vectors exhibited consistently higher leakage rates across all treatments, but MG-2.2-009 frames synthetic data as a uniform risk category rather than one with meaningfully different exposure profiles by source
No incident response protocols exist for governance-intervention-induced regressions: the instance-based alignment treatment produced higher leakage than the unprotected baseline, a failure event that current frameworks oriented toward deployed model outputs would not identify as reportable
MG-4.1-002 on post-deployment monitoring focuses on cyber risks and does not include adversarial PII extraction as a monitored risk category, despite the evaluation demonstrating that applicable monitoring tools exist
The project produced a 33-page governance analysis with empirically grounded findings across two phases: a NIST AI RMF gap analysis covering all four framework functions, and nine actionable recommendations for organizations, practitioners, and policymakers. The central finding was that synthetic rephrasing does not eliminate PII risk, it redistributes it in ways that evade current detection practices while remaining reconstructable by models trained on the data. And the governance frameworks meant to prevent this have not caught up.

ReflectionREFLECTION
What I took away from this project was that synthetic data governance is not principally a technical problem waiting for a technical solution. It is a framing problem. The same mechanism, template-based rephrasing, per-snapshot deduplication, gradient noise, can be characterized as a quality optimization or a privacy amplification dynamic depending on who is doing the framing. Current frameworks have inherited the framings of the technical communities that produced the techniques rather than re-examining them through a privacy lens. That is where the gaps live.
I also came away with a clearer sense of what empirical evaluation can and cannot do for governance work. The 10-individual fictional corpus and 65-prompt battery are not generalizable findings. They are existence proofs that the conditions under which governance gaps become consequential are reachable in realistic deployment configurations. That is a different kind of contribution than a literature review, and for me it was the more interesting one to work on.

AppendixFinal Report File