Retrieval-Augmented Generation (RAG) for Algorithmic Bias and Fairness in Public Services
OverviewRoleTimelineBACKGROUND
This project came out of a graduate course at CMU where I built a Personal Research Portal, a RAG-powered system that ingests academic sources, retrieves evidence semantically, and generates citation-backed answers. I chose algorithmic bias and fairness in public services as my research domain, making this as much an intellectual exercise as a technical one. It's also where I finally got to build the thing I wished I had on the WIC project: a real, working retrieval pipeline grounded in real sources.
I owned this project end to end, from research domain selection and prompt design through pipeline engineering, evaluation, and the final portal build. Every architectural decision, metric, and failure analysis was mine.
6 weeks
OUTCOME
The final system ingests academic sources, retrieves evidence using hybrid BM25 and semantic search, and returns citation-backed answers exportable as Markdown, CSV, or PDF. Built across three phases, it went from a prompt engineering study to a fully functional four-page Streamlit research portal, hitting 100% answer rate and 100% citation correctness by Phase 3 across a 26-source corpus on algorithmic bias in public services.
The Problem I Set Out to SolveI had spent a semester designing an AI system for advocacy work and never got to build the part that would make it actually trustworthy. I wanted to know if I could build one in practice, one that retrieved precisely, cited honestly, and refused to guess when the evidence wasn't there. For the research domain, algorithmic bias in public services was the obvious choice. It sits at the intersection of everything I care about, responsible AI, policy, and the communities that welfare systems like WIC are built to serve.
Building the SolutionPHASE 1: Prompt Engineering and Task Design
Before writing any pipeline code, I spent Phase 1 stress-testing how well LLMs could handle research tasks with no retrieval layer underneath them. I designed a research domain around algorithmic bias in public services, defined a main research question and four sub-questions, and selected two core tasks: claim-evidence extraction and cross-source comparison. For each task I wrote two prompt versions, a basic version and a structured version with guardrails, and ran both across two models for a total of 16 test runs. The key finding was that structured prompts with explicit output constraints significantly reduced hallucination and improved citation behavior, but without retrieval, even well-prompted models fabricated sources under pressure. That finding became the foundation for Phase 2.
PHASE 2 : Building the RAG Pipeline
Phase 2 was where I built the core retrieval system. I curated a corpus of 26 sources including academic papers, policy documents, and government reports spanning 2017 to 2025, and ran them through a full pipeline: PDF ingestion, 300-word chunking with 50-word overlap, embedding with all-MiniLM-L6-v2, and vector indexing with FAISS. I then designed a 20-query evaluation set across three categories, direct questions, synthesis questions, and edge cases, and measured performance on groundedness, citation correctness, and answer coverage.
The results were honest. Citation correctness hit 100%, but answer coverage landed at 60% and groundedness at 65.5%. The system was retrieving the right sources but failing to synthesize them into readable answers, returning raw PDF excerpts, mid-sentence chunks, and bibliography dumps instead of coherent responses. I documented every failure pattern in detail and used them to drive the Phase 3 roadmap.
PHASE 3: Hybrid Retrieval and the Research Portal
Phase 3 directly addressed what Phase 2 revealed. The two biggest improvements were hybrid retrieval and a full Streamlit portal.
For retrieval, I replaced pure semantic search with a hybrid system combining FAISS vector search at 70% weight and BM25 keyword scoring at 30%, with a configurable alpha slider so users could adjust the balance based on their query type. The intuition was straightforward: semantic search captures conceptual similarity but dilutes domain-specific terminology across the embedding space. A query for "NIST AI RMF" might match chunks about AI governance generally rather than the specific framework document. BM25 anchors retrieval to exact term matches, which matters a lot in a technical domain like AI governance where precise language carries precise meaning. The blend raised average confidence from 0.629 to 0.891, a 41.7% improvement, and brought answer rate from 60% to 100%.
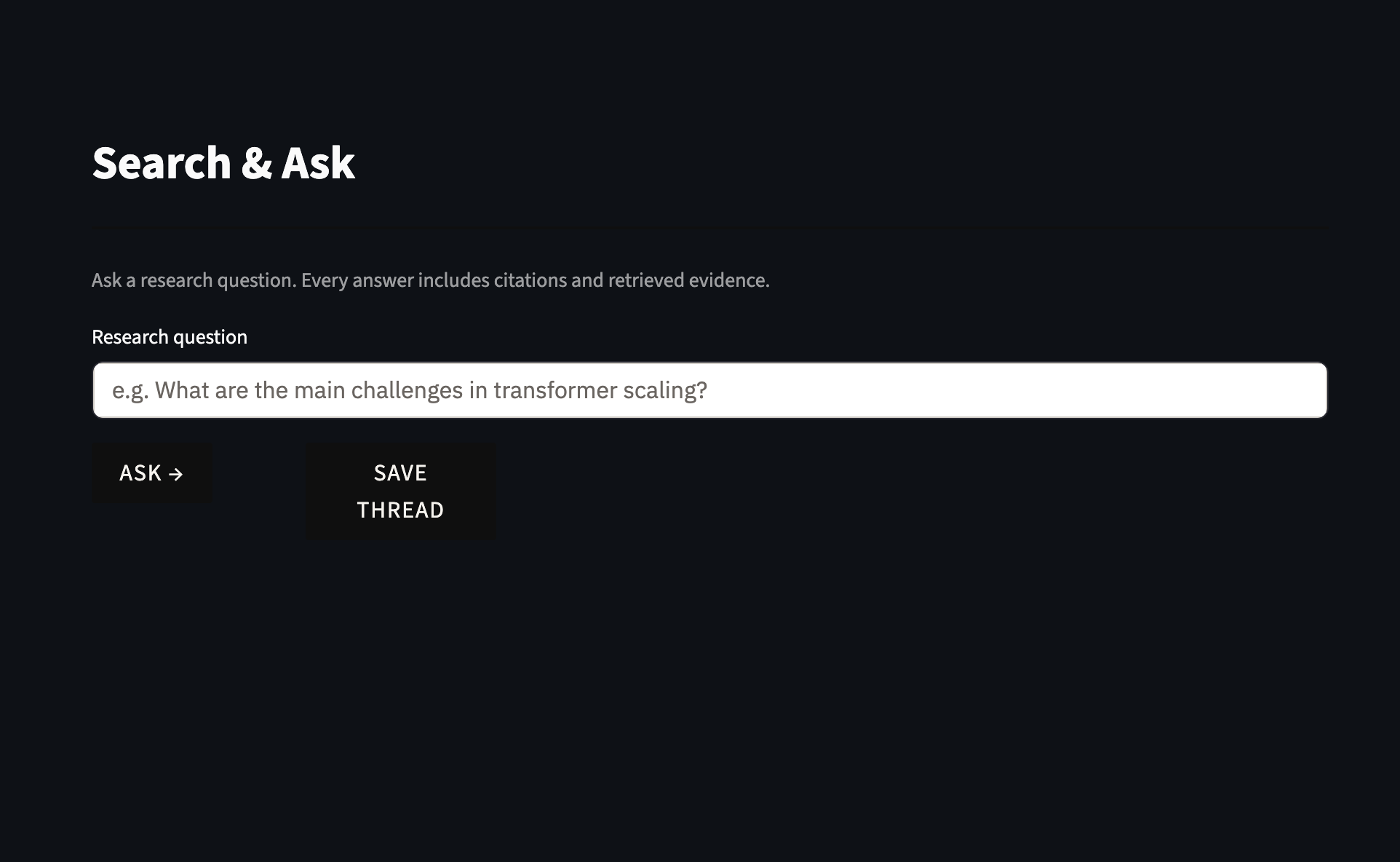
I also built a four-page Streamlit portal with custom academic CSS styling supporting the full research workflow. The Search and Ask page handles natural language queries and returns cited answers with inline evidence chunks. The Evidence Table page generates a structured artifact mapping each claim to its exact source chunk, with a user-editable notes column for researcher annotation, exportable as Markdown, CSV, or PDF. The Research Threads page persists query session history as JSON files. The Evaluation page runs the full query set automatically and displays a metrics dashboard with failure category breakdowns.
One of the design decisions I was most deliberate about was how the system handles cases where it cannot answer. Rather than returning a generic error, I built a four-category failure classification system that diagnoses why a query failed and surfaces a specific remediation path. Retrieval failure, corpus gap, generation refusal, and low confidence each trigger a different message and a different suggested fix. In Phase 3 the failure categorization was never triggered because hybrid retrieval resolved every Phase 2 failure case, but the framework is in place for future query sets and filtered retrieval scenarios.
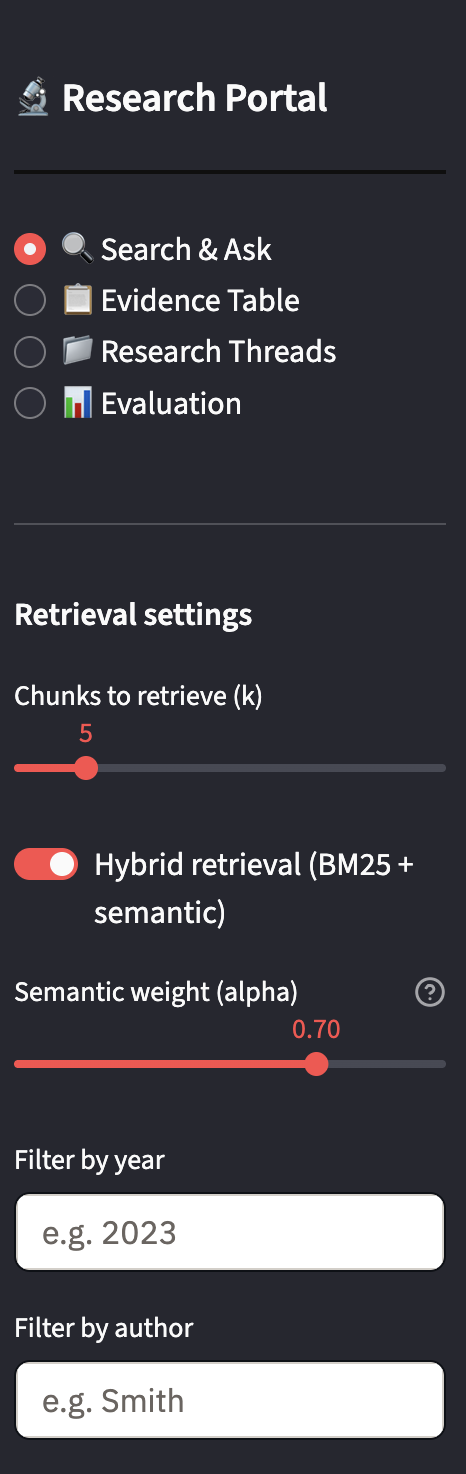
The left sidebar shows the portal's four-page navigation alongside configurable retrieval settings: a chunks-to-retrieve slider, a hybrid retrieval toggle combining BM25 and semantic search, and a semantic weight alpha slider set to 0.70.
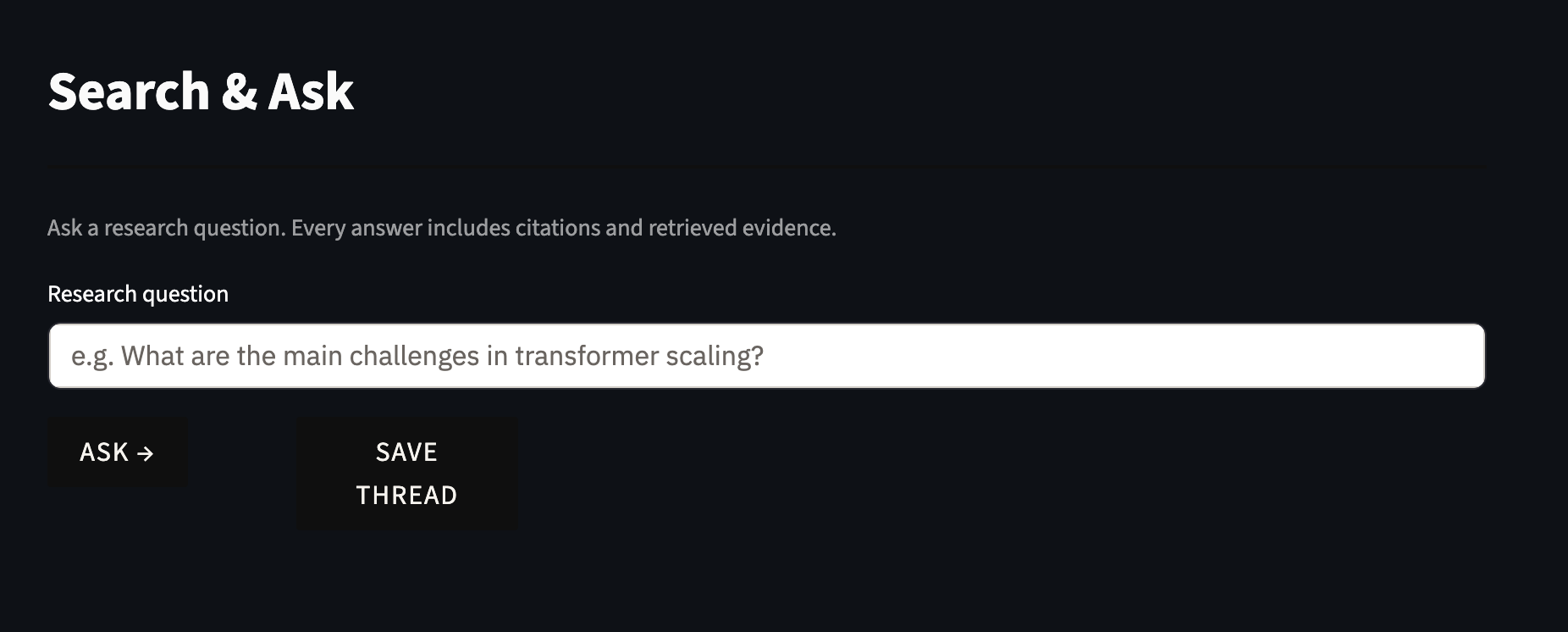

The Search and Ask page is the main entry point where users type a natural language research question and get back a cited answer. Below it, the Research Threads page shows saved query sessions with timestamps, giving researchers a persistent record of everything they have asked and what the system retrieved.
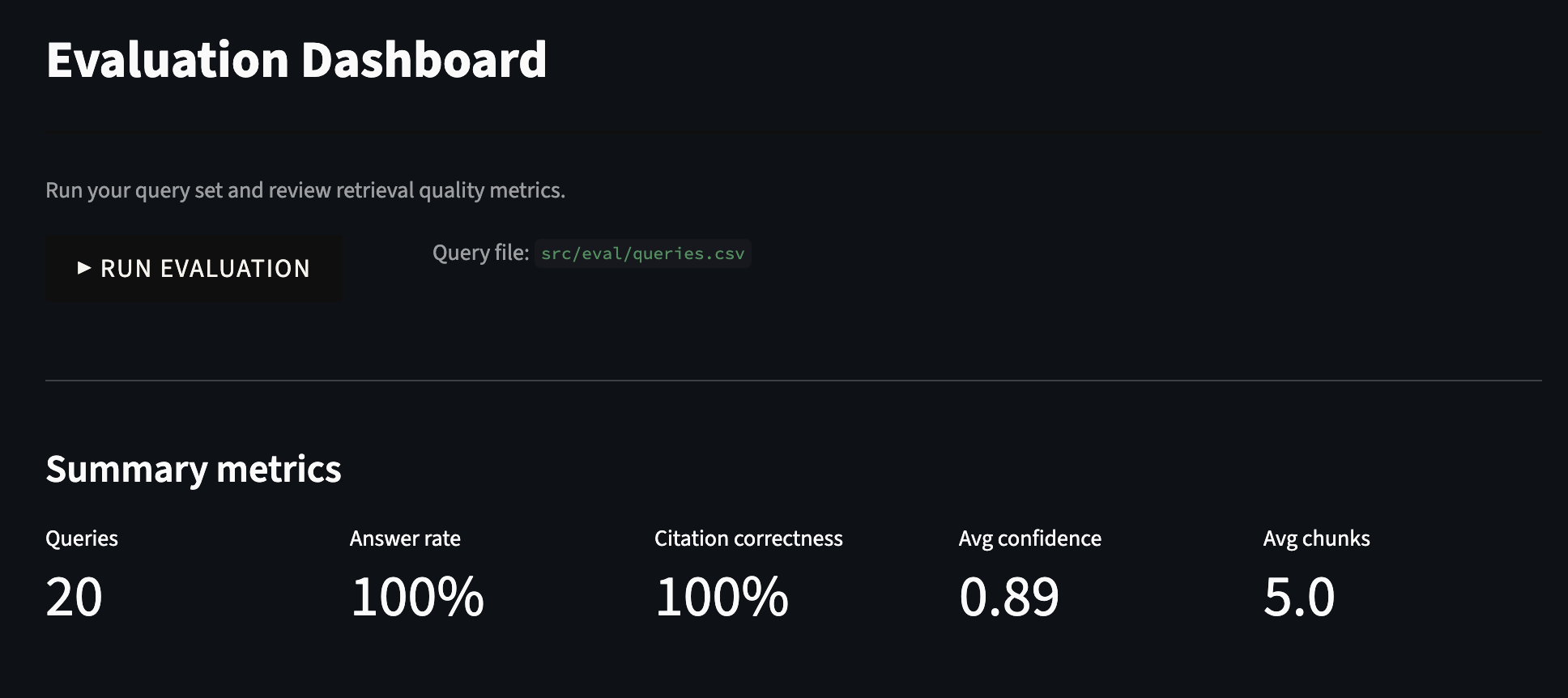
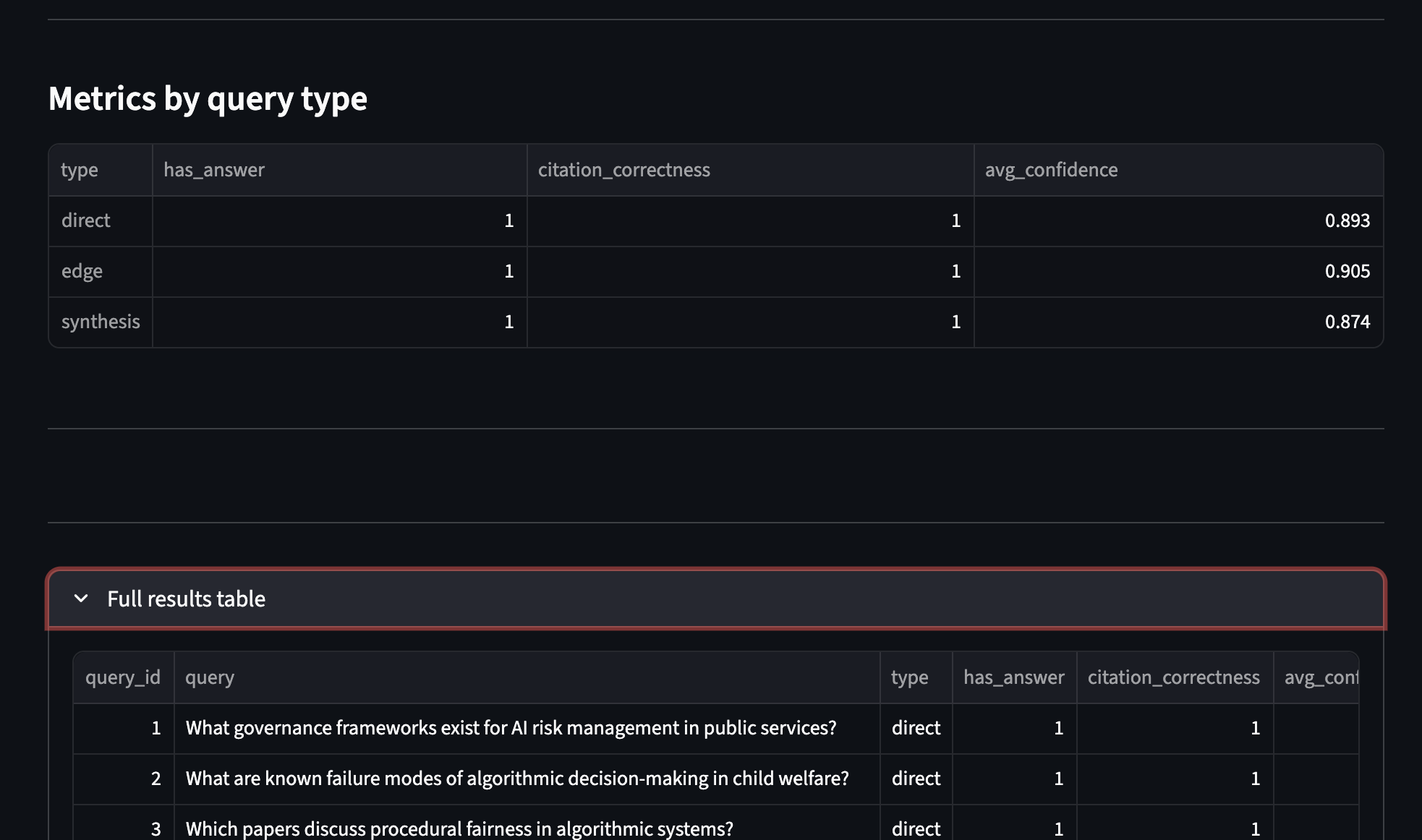
The Evaluation Dashboard runs the full 20-query set automatically and surfaces summary metrics at a glance: 100% answer rate, 100% citation correctness, and an average confidence of 0.89 across all queries.
The metrics by query type table breaks performance down further, showing that results held consistently across direct, edge, and synthesis queries, with edge queries leading at 0.905 confidence and synthesis queries close behind at 0.874. The full results table at the bottom gives a per-query view for anyone who wants to dig deeper.
Takeaways + ReflectionHybrid Retrieval Resolved Every Phase 2 Failure
Pure semantic search was diluting domain-specific terminology across the embedding space, causing 40% of queries to return raw PDF excerpts or bibliography dumps instead of usable answers. Replacing it with a 70/30 blend of FAISS vector search and BM25 keyword scoring resolved all 8 failure cases, raised average confidence by 41.7%, and brought answer rate from 60% to 100%.
A Failure Diagnosis System That Actually Tells You Why
Most RAG systems return a generic error when they cannot answer. I built a four-category failure classification system that diagnoses the specific reason a query failed and surfaces a targeted remediation path. It was not triggered once in Phase 3, but designing it forced me to think rigorously about every way the system could break down, and that thinking made the rest of the architecture better.
REFLECTION
This project taught me what it actually means to build a trustworthy AI system, not just a capable one. Getting to 100% citation correctness mattered more to me than getting to 100% answer rate, because a system that retrieves confidently but fabricates sources is worse than one that admits it does not know. Every architectural decision I made, from hybrid retrieval to failure categorization to the user-editable evidence table, was oriented around that same principle: the system should never ask the user to trust something it cannot verify.
The clearest piece of unfinished business is answer synthesis. The TA feedback named it directly: answers are extractive, concatenated chunks rather than LLM-synthesized prose, and that limits fluency even when retrieval is working well. The Anthropic SDK was already in my dependencies. The next step is straightforward: pass retrieved chunks as context to a language model and prompt it to synthesize a coherent response rather than surface raw text. I also want to persist the BM25 index to disk rather than rebuilding it on every startup, which would meaningfully reduce latency on larger corpora.
It also gave me a much more grounded understanding of where RAG systems actually break down in practice. The gap between retrieval and synthesis is real, and closing it requires more than a better prompt. That is the problem I am most interested in continuing to work on.

AppendixGitHub Repository - lanayaoj /AIMD-RAG